
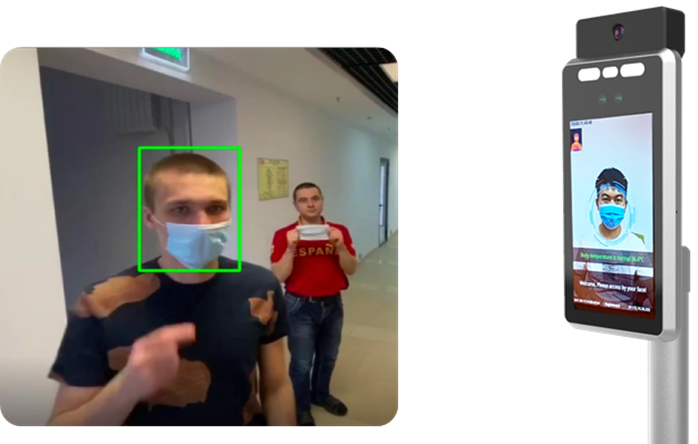
By using such a device, a business can significantly ease visitor flow and simplify the work of security guards, store attendants, and other staff that is responsible for ensuring that people wear masks and that sick visitors do not enter the premises.
At the same time, to ensure that the device is affordable for as many users as possible, it was vital to ensure that low-cost, readily accessible hardware can be used.
Task:
MobileNet_v2_SSD, a lightweight model based on MobileNet_v2, was chosen as the underlying neural network for face mask detection (or lack thereof). After initial testing, it provided an accuracy of 0.88 (average precision) on the validation dataset. This level of accuracy was satisfying, but the size of the model didn't allow inference on the terminal itself. Therefore, all computing had to be transferred to remote servers.
Sending data to a remote server takes time, which can severely impact the store visitor experience. In turn, cloud computing adds unnecessary recurring costs, while processing on a server located on the premises adds unnecessary complexity and setup costs. The company desired to ship a product that can be used out of the box, without any additional setup steps or costs involved for the users.
Thus, the main goal of the partnership was to compress the neural network to a size that would allow computing on the target device (ARM Cortex A52 1.2GHz). In turn, it was proposed to increase the speed of the underlying neural network as much as possible to minimize waiting time as much as possible, when it comes to a visitor being allowed to enter the premises.
Main technical parameters
- accuracy - average precision;
- number of required computational operations - MMAC;
- model Size - Mb;
- frame rate - FPS;
- neural network depth - layers.
Input data from the customer
- hardware - ARM Cortex A52 1.2GHz;
- the architecture of the neural network - MobileNet_v2_SSD
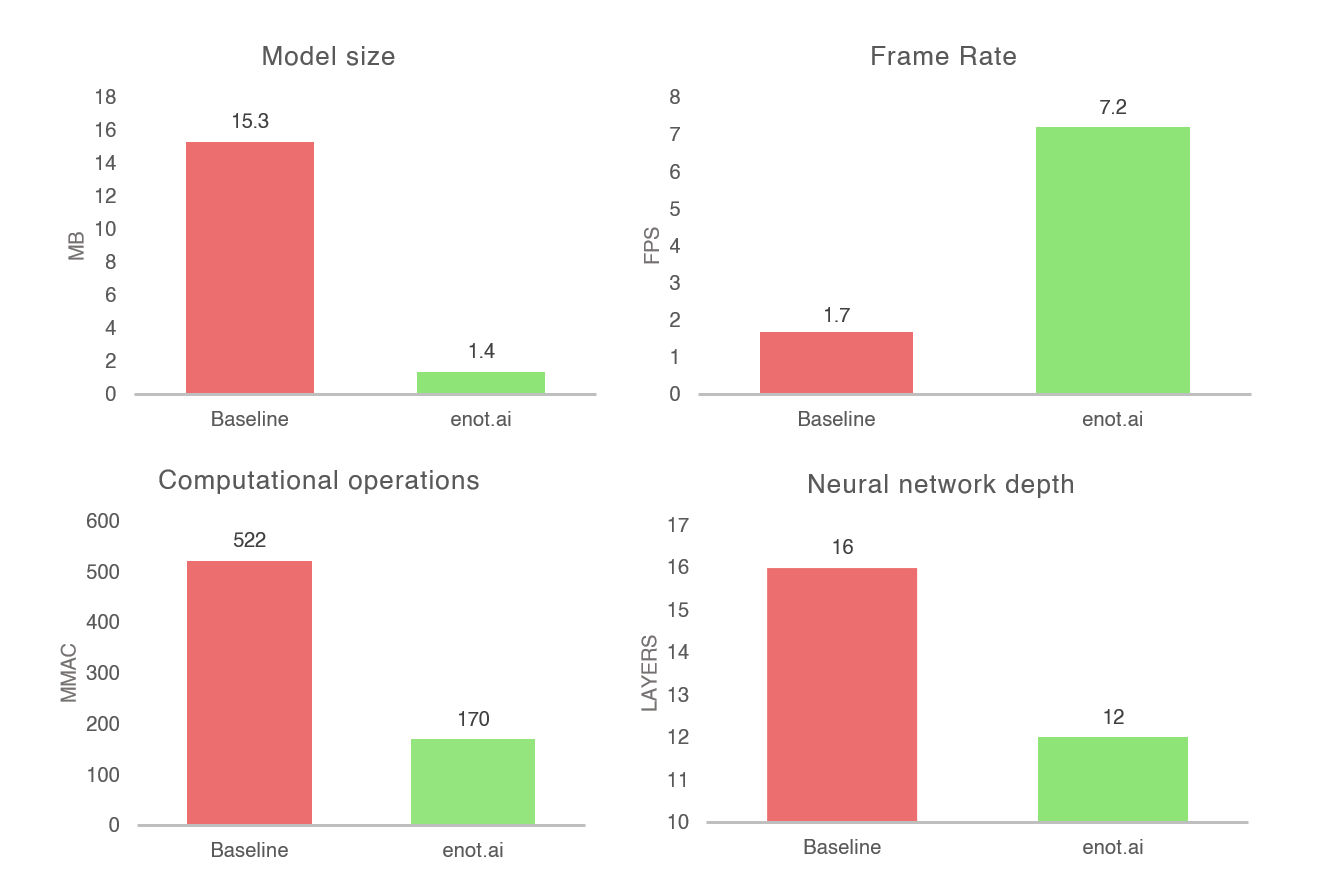
- framerate - 1.7FPS
- model size - 15.3 Mb
Target: decrease the model size to a value that allows inference on the terminal itself, and increase the frame rate as much as possible.
Results
Both neural network depth and the number of required computational operations (MMAC) were reduced, as the model was compressed 10.9 times and accelerated 4.2 times.
At the same time, accuracy remained at basically the same level (0.88 for baseline and 0.87 for enot.ai’s optimized model).
Summary
After applying enot.ai’s technology, the company was able to successfully deploy a neural network for face mask detection on an ARM Cortex A52 1.2GHz chip with real-time, on-premises processing, ensuring an easy-to-use and affordable device with a seamless face mask detection experience.