
For those who are not familiar, ADAS is an automated electronic system that assists the driver and makes driving safer. By using cameras and sensors, the system monitors the road and warns the driver about other vehicles, red lights, lane departures, and other potentially dangerous situations. When it comes to ADAS as such, speed and accuracy are crucial, thus each unit of acceleration that is gained is vital for the performance of the underlying neural networks.
Task: In the case of LG, neural networks were being used to segment the input images and recognize objects in the video, and the requirement was to speed up video processing without a loss of accuracy and without changing the neural network architecture and the hardware used.

Main technical parameters
- accuracy of object detection and segmentation - IoU;
- the time it takes to process one frame - latency (ms/frame).
Input data from the customer
- Hardware - Nvidia Jetson TX2;
- Inference engine - TensorRT;
- The architecture of the neural network - Unet;
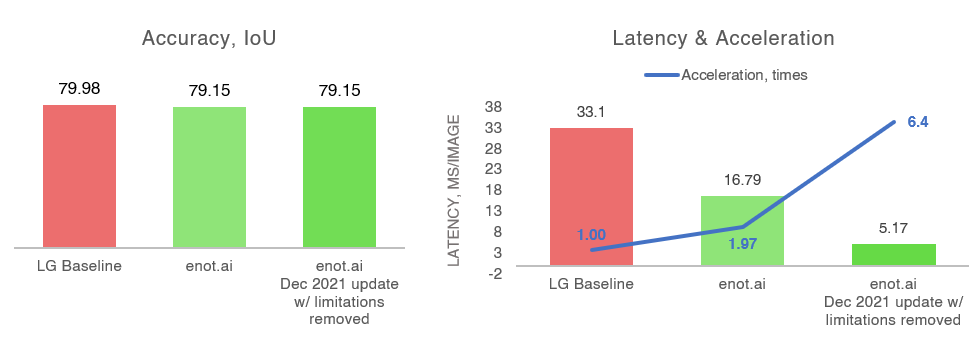
- Processing time per frame - 33.1 ms/frame.
Target:
reduce processing time per frame as much as possible, without changing the hardware or the neural network architecture type.
Limitations during process
In the course of the project, we faced some limitations:
- The acceleration was limited by the hardware itself, as Nvidia Jetson TX2 doesn’t support inference in INT8;
- LG requested that the inference engine wouldn’t be changed;
- Input resolution was not to be changed;
- The underlying Unet model has limited acceleration due to architecture features, such as skip-connection doesn’t allow changing the number of neural network layers in the decoder block. - the December 2021 update has added support for this feature.
Results
Taking into account LG’s requirements and the aforementioned limitations,
the time to process a video frame was reduced to 16.79 milliseconds per frame
with basically zero accuracy loss.
After optimization, enot.ai accelerated the neural network 1.97 times.
Further improvements
To further accelerate the underlying neural networks, one or more of the following actions could have been done:
- By choosing different hardware, an additional 1.3x acceleration could have been achieved. As mentioned before, Nvidia Jetson TX2 doesn’t support inference in INT8;
- By changing input resolution, another 1.25x acceleration could have been achieved;
- Our software’s most recent Dec 2021 update has addressed skip-connection related to Unet, thus granting another 2.00x acceleration.
Important to note that if limitations were to be removed
and the project was carried out again by using our most recent product update,
the total acceleration would reached 6.4 times!
Summary
LG did not have to change either the hardware, or the underlying neural network model, or the architecture itself. Meanwhile, the accuracy of detection and segmentation of objects remained high, and the speed of the system basically doubled. In turn, if all limitations were removed and the most recent software version would be used, the acceleration would have reached 6.4 times.