
We partnered with a major mobile device manufacturer* that sells its devices in almost all countries around the world. During this project, the company required optimization of the underlying neural network model that was used as a part of an image enhancement process for all photos that are located in the library of a phone.
Given consumer behavior, real-time edge processing is essential for enhancing mobile phone users’ experience.
*Unfortunately, we cannot disclose the name of the company due to an NDA.
Task:
The underlying neural network is used in the first stage of image processing, and it acts as a filter, which is then applied to each photo.
Since the neural network processes every single image, the company had strict requirements:
- high accuracy: in case of a classification error, the photo would be processed incorrectly at the very start, thus the user will be dissatisfied with the quality of the images;
- high speed: absolutely all photos pass through the model, thus the processing pipeline must be fast. Otherwise, the user will be unhappy with the speed of the device;
- small size: mobile devices have limited RAM capacity, thus model size has to be very low.
Main technical parameters
- accuracy - processing accuracy;
- inference time - ms;
- neural network depth - layers;
- bit depth - bits
- Input resolution - 224×224;
- processing accuracy — not less than 99%;
- time required to process one image (inference time) — no more than 10 ms;
- model size — no more than 5 Mb.
Target: decrease model size and the time required for processing one image, while maintaining very high accuracy.
Results
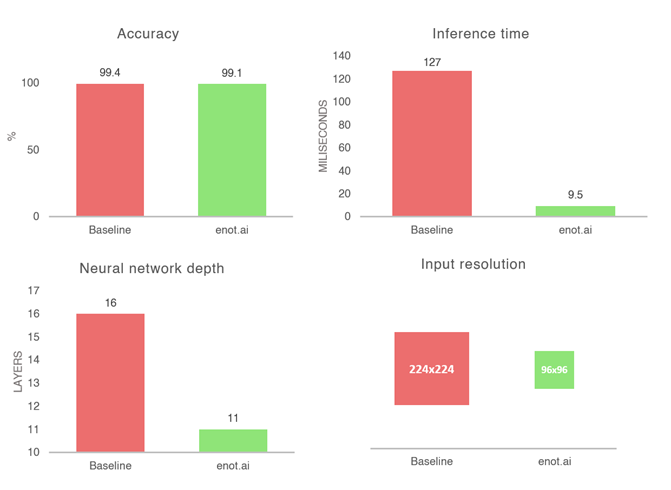
The main challenge in such a case is to simultaneously create a very accurate (>99%) and a very fast neural network (<10ms, <5Mb). For the purpose of this task, MobileNet_v2 was chosen as the architecture of the neural network. By using enot.ai’s technology, it was possible to identify and select the architecture that met the customer’s strict requirements, as there was barely any accuracy loss (99.4% > 99.1%), inference time was reduced from 127ms to 9.5ms, while neural network depth, bit depth, and input resolution was reduced, resulting in 13.3x acceleration. Furthermore, enot.ai made it possible to reduce the input resolution from 224x224 to 96x96.
Summary
After applying enot.ai’s technology, the company was able to successfully deploy a neural network at the first stage of image processing of an image enhancement process with a resulting acceleration of 13.3 times.